
HPC meets interactive Data Science and Machine Learning
Carme (/ˈkɑːrmiː/ KAR-mee; Greek: Κάρμη) is a Jupiter moon, also giving the name for a Cluster of Jupiter moons (the carme group).
or in our case…
an open source framework to manage resources for multiple users running interactive jobs on a Cluster of (GPU) compute nodes.
This documentation is divided in the following sections:
Introduction
Documentation
Team
Carme Presentation
Carme is simple and easy to use. Take a look at our Dashboard page.

With 2 clicks you are already working in your project using HPC resources. Refer to our marketing slides for more:
Core Idea
We combine established open source ML and DS tools with HPC backends and use therefore
- Singularity containers
- Anaconda environments
- web–based GUI frontends e.g. Code-Server and JupyterLab
- completely web frontend based
(OS independent, no installation on user side needed) - HPC job management and schedulers (SLURM)
- HPC data I/O technologies like Fraunhofer’s BeeGFS
- HPC maintenance and monitoring tools
Job submission scheme
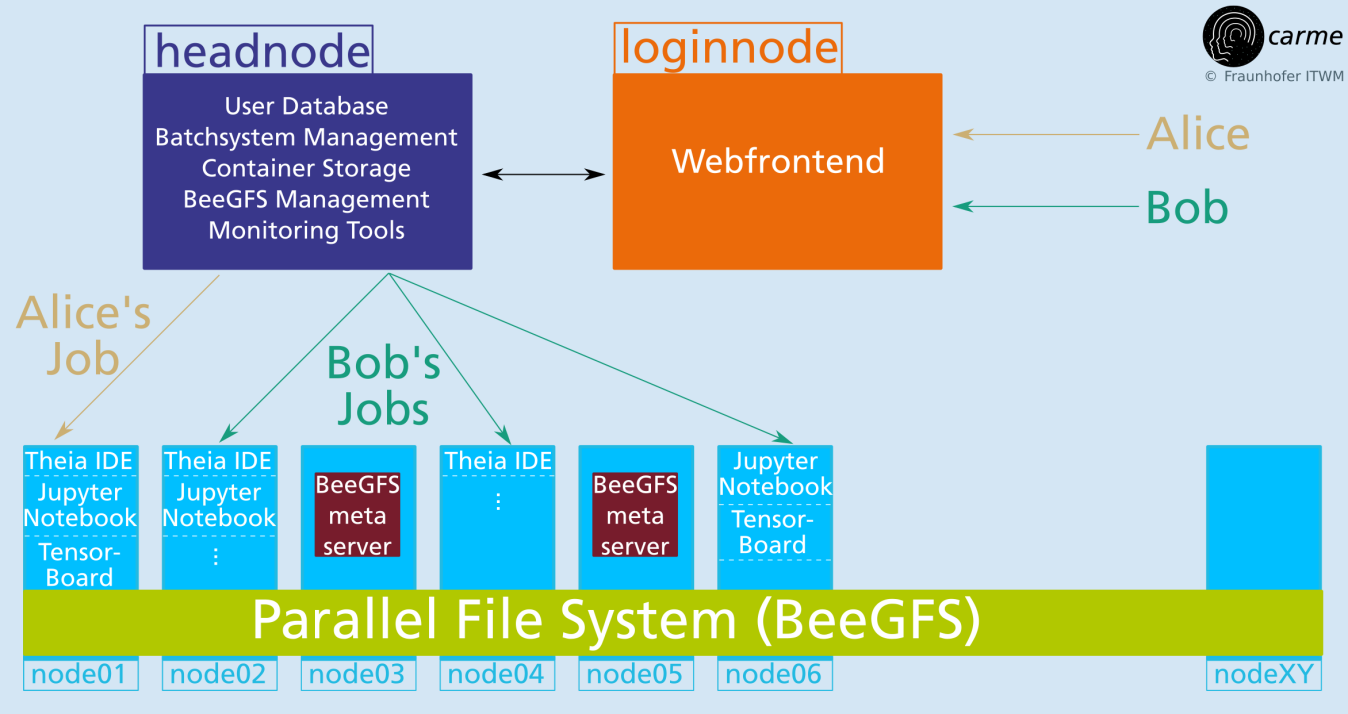
Key Features
- Open source
- we use only open source components that allow commercial usage
- Carme is open source, allowing commercial usage
- Seamless integration with available HPC tools
- Job scheduling via SLURM
- Native LDAP support for user authentication
- Integrate existing distributed file systems like BeeGFS
- Access via web-interface
- OS independent (only web browser needed)
- requires 2FA
- Full user information (running jobs, cluster usage, news / messages)
- Start/Stop jobs within the web-interface
- Interactive jobs
- Flexible access to accelerators
- Access via web driven GUIs like code server or JupyterLab
- Job specific monitoring information in the web-interface
(GPU/FPGA/CPU utilization, memory usage, access to TensorBoard)
- Distributed multi-node and/or multi-gpu jobs
- Easy and intuitive job scheduling
- Directly use GPI, GPI-Space, MPI, HP-DLF and Horovod within the jobs
- Full control about accounting and resource management
- Job scheduling according to user/project specific roles
- Compute resources are user/project exclusive
- User maintained, containerized environments
- Singularity containers
(runs as normal user, GPU, Ethernet and Infiniband support) - Anaconda Environments
(easy updates, project / user specific environments) - Built-in matching between GPU driver and ML/DL tools
- Singularity containers
How to install Carme
Refer to our installation documentation.
How to use Carme
Refer to our documentation.
Roadmap
Current release:
- 11/2024
- Carme-demo 1.0:
- Installation script to test Carme in Debian and RedHat based systems. Refer to our installation documentation.
- Adapted to GPU clusters with pre-set SLURM and MySQL.
- Adapted to multi-users in Debian based systems.
- Adapted to single-users in RedHat based systems.
- Carme r1.0:
- Jupyter notebooks start in the Home directory.
- Carme-demo 1.0:
Next release:
- 04/2025
- Carme-demo 1.1:
- Adapted to systems with pre-existing LDAP.
- Carme r1.1:
- Carme runs in AWS (Amazon Web Services).
- Carme-demo 1.1:
Releases
-
04/2018: Carme prototype at ITWM
-
03/2019: r0.3.0 (first public release)
-
07/2019: r0.4.0
-
11/2019: r0.5.0
-
12/2019: r0.6.0
-
07/2020: r0.7.0
-
11/2020: r0.8.0
-
08/2021: r0.9.0
-
05/2022: r0.9.5
-
09/2022: r0.9.6
-
08/2023: r0.9.7
-
12/2023: r0.9.8
-
06/2024: r0.9.9
-
11/2024: r1.0 (latest)
Authors
Carme is developed by the Competence Center for High Performance Computing at Fraunhofer ITWM.
![]()
Contact
Sponsors
The development of Carme is financed by research grants from
![]()
![]()